Step-by-Step Full Course. All Parts. 📚 46 Lessons

Description
🎓 This course is intended to be an initiation to learn #BigData and #MachineLearning with #Python programming for absolute beginners that have no background in programming.
In this course, we will step by step, using the example of real data, we will go through the main processes related to the topic “Big data and machine learning”. Since the material turned out to be voluminous, I divided the course into five parts.
📑 The first part is devoted to the collection and extraction of data from documents.
✔️ In this course, you will learn how to extract data from PDF documents, drawings and any other documents in PDF format. We will have two sets of data consisting of PDF files that we will transform to the text and to tabular form. We will visualize the received data on the Kaggle platform using python libraries, which will help us to depict our received data in a graphical format.
✔️ During the training process, we will install Python and such libraries as Pandas, seaborn, matplotlib and others. We will upload the received data to the Kaggle platform and here using the “Jupiter Notebook” we will visualize our data and at the end, we will upload our data to the GitHub platform.
📑 The Second part is devoted to the collection and extraction of data from scanned documents and Images. In this course, you will learn how to extract data from From Scanned Documents And Images, invoices, receipts, contracts and any other documents in PDF format or in Image format.
✔️We will work on real data. We will have two sets of data consisting of PDF files that we will transform to the text and to tabular form. We will visualize the received data on the Kaggle platform using python libraries, which will help us to depict our received data in a graphical format.
✔️ During the training process, we will install Python and such libraries as Pandas, seaborn, matplotlib and others. We will upload the received data to the Kaggle platform and here using the “Jupiter Notebook” we will visualize our data and at the end, we will upload our data to the GitHub platform.
📑 In third part we will consider the main options for storing big data.
✔️ In practical lesson we will install the MySQL server on computer and learn how to work and edit MySQL databases.
In the fifth lesson we will take one regular exel table and transfer the information from this table to the MySql server.
✔️ Then we will install the spark in order to work with datasets in a distributed manner.Then, to process the distributed data, we export the data from MySQL into spark. And with the help of Jupiter Notebook, we prepare the data for visualization of this data.
📑 In fourth part we will look at the main platforms for visualizing Big Data and consider the main Data Visualization Online-Tools for Big Data.
✔️ We will briefly look at these platforms and generate several reports in each of the platforms. This will give you the opportunity to choose the right platform that suits you and your data.
✔️ In practical lesson we exported an excel file with our data to the Kaggle platform and using a Jupyter Notebook we cleared the data and visualized the data using different python libraries.
📑 In fifth part we will examine in detail the basic types, terms and algorithms of machine learning. We go through the basic concepts of machine learning that beginners need. We will consider in more detail such algorithms as K-means supervised Machine Learning, Linear Regression and other algorithms for Machine Learning.
✔️ In practical lessons we will predict the time and cost of construction for the new project X, based on the data that we collected on previous projects. And in another lesson we will predict the cost of building project X and construction time by the parameters that we will set for the new project x
✔️ Then we take open source data for the San Francisco city. We will clear this raw data and display the data in the form of a charts and maps. We will collect various interesting insights from this public information. Then we will prepare the data to create a machine learning model and try to predict some parameters from this data.
📦 Learning Resources

🔎 Topics covered in this course:
- How to convert a PDF to text?
- Python or Anaconda?
- What is the best Python IDE for beginners?
- How do I install VS Code?
- How do I install Python?
- How to run Python in VS Code?
- How does Python interpreter choose VS code?
- How do I convert a PDF to TXT in Python?
- How can I iterate over files in a given directory?
- Install Apache Tika on Windows.
- How to split a string into a list?
- Remove blank strings from a list?
- What is regular expression with example?
- How to match regular expression in Python?
- Debug a regular expression in Python?
- What is the regular expression for date format?
- How do you check if an array contains a regular expression?
- Create loop with regular expression.
- How do you add a string to an array?
- How do you find the index of an element in a list?
- How can I extract the date from a string?
- How to declare and add items to an array in Python?
- How do you write a function in Python?
- How to install pandas on Python?
- How do I create a pandas DataFrame?
- How to reduce number of columns in a pandas DataFrame?
- How to combine column values into a list in a new column?
- How to convert array into DataFrame in Python?
- How to change column names in pandas Dataframe?
- How do I save a Dataframe as CSV table?
- How do I upload a file to kaggle kernel?
- How do you use kaggle dataset?
- How to run Jupyter notebook using Kaggle kernels?
- How to convert a CSV to dataframe in Python Jupyter Notebook?
- How to use the functions of Pandas Dataframe?
- How do I change the date format of a column in pandas?
- How do I convert a string to datetime Objects in Python?
- How to Calculate Difference Between Two Dates in Pandas Dataframe?
- How do I delete a column in pandas DataFrame?
- How do I add columns in pandas DataFrame?
- How do you visualize a dataset?
- How do you plot a DataFrame in pandas?
- Independent Work Tasks
- Learn to Code – on real data (16 PDF files to chart)
- A brief overview of the data in the task
- What is GitHub and how do you use it?
- What can I use GitHub for?
- How do I upload files to GitHub?
- How to install GitHub Desktop?
- How to sync with a remote Git repository?
- Ho adding a repository from your local computer to GitHub?
• How to convert a scanned PDF to text?
• Python or Anaconda?
• Choosing an Python IDE for beginners.
• How to install Visual Studio Code on Windows?
• How to install Python?
• How to run Python in VS Code?
• How to convert scanned PDF to JPEG?
• How to Install Tesseract OCR?
• What is Tesseract?
• Google OCR in Python with Tesseract.
• Extract a page from a pdf as a jpeg
• How to convert a pdf document to images using python?
• Convert PDF to Image using Python.
• Install Poppler, Pillow (PIL) module.
• Installing Tesseract for Windows
• Install PyTesseract OCR.
• Iterate over files in a given directory.
• How is try/except used in Python?
• Writing user-defined functions in Python
• What is regular expression?
• How do you match in regex?
• Online RegEx tester and debugger.
• Use Findall in Python?
• Using Regex for Text Manipulation in Python.
• Add a string to an array.
• How to declare and add items to an array in Python?
• Write a function in Python.
• Save data to Pandas Dataframe.
• How do I convert address to coordinates?
• How do you geocode data?
• Locate the coordinates.
• How do I find the geocode of an address?
• Install GeoPy module.
• Install GDL, Fiona module.
•Visualize a dataset.
•Run Jupyter notebook using Kaggle.
• Python Treemaps with Squarify and Matplotlib.
• How do you create a TreeMap chart?
• How to Convert Strings to Floats in Pandas DataFrame.
• Replacing strings with numbers in Python
• Plot a DataFrame with matplotlib and seaborn.
• Plot Geographic Data on a Map.
• How to use folium with Jupyter notebook?
• Placing coordinates on a map.
• How to plot data on maps in Jupyter.
• Efficiently display a map with CircleMarker().
• Mapping in Python with geopandas.
• Black & White map with Folium.
•GitHub and how do you use it.
•Upload files to GitHub.
•Install GitHub Desktop.
•Sync with a remote Git repository.
•Adding a repository from your local computer to GitHub.
- What is big data?
- What storage options we have today?
- Public Cloud and Private Cloud.
- Distribute you data
- What is MySQL?
- How Does MySQL Work?
- Why is MySQL so Popular?
- MySQL server setup
- Initial settings
- Getting Started with MySQL
- Import Excel data into a MySQL
- Create a new MySQL table.
- Most Common Queries.
- SELECT, DROP, UPDATE query mysql
- What is Hadoop?
- Spark vs MySql
- Spark. Analytics engine for big data processing
- Installing Apache Spark
- updating PATH environment
- Getting Started with Spark
- Launching Apache Spark
- Installing Anaconda On Windows
- Running the Jupyter Notebook
- Connecting Jupyter notebook to Spark
- Connecting Jupyter notebook to Spark
- How to set up PySpark for your Jupyter Notebook
- Export Data from Mysql to Spark
- Importing Spark Dataframes from MySQL on Jupyter notebooks
- What is Business Intelligence?
- Data Visualization Tools
- Was ist Business Intelligence? Was ist BI?
- Jupyter Notebooks as a Custom Calculation Engine
- Machine Learning Visualizations made in Python
- Export data from Excel to Python
- Uploading data to Visualizations on Kaggle
- Introduction to Jupyter Notebooks
- Prepare data for Visualisations
- Clean data for Visualizations
- Use Pandas in Jupyter Notebook
- Data Cleaning With Pandas
- Visualization with Seaborn and Matplotlib
- Data visualization by Heatmaps and Scatter plots
- Python Treemaps with Squarify
- Three-Dimensional Plotting in Matplotlib
- Pros and Cons of Power BI
- Import an Excel file into Power BI
- How to Get Started
- Treemaps in Power BI
- Creating Reports in Power BI
- Pros and Cons of Tableau
- Import an Excel file into Tableu
- How to Get Started in Tableu
- Treemaps in Tableu
- Creating Reports in Tableu
- Creating Dashboards in Tableu
- Pros and Cons of Google Data Studio
- Import an Excel file into Google Data Studio
- How to Get Started in Google Data Studio
- Treemaps in Google Data Studio
- Creating Reports in Google Data Studio
- Creating Dashboards in Google Data Studio
- What is machine learning?
- Key ML Terminology
- Supervised Machine Learning
- Unsupervised Machine Learning
- Reinforcement Learning
- Jupyter Notebooks for Data Science
- Introduction to Kaggle for Beginners in Machine Learning
- Supervised learning: predicting an output
- Predict the price of a house
- Prediction of time and cost for small training dataset
- K-means supervised Machine Learning algorithm
- Understanding K-means Clustering in Machine Learning
- Overview of Machine Learning Algorithms
- Getting started with Machine Learning in MS Excel
- A Kaggle Walkthrough – Cleaning Data
- Beginner’s Guide to Jupyter Notebooks
- Train, Validation Sets in Machine Learning
- Splitting data into Training & Validation
- Determined the cost and time of construction work for project X
- Evaluation Metrics for Machine Learning Model
- Linear Regression for Machine Learning
- How our algorithm works visually
- Creating and Visualizing Decision Trees
- Stages of the Machine Learning Modeling Cycle
- Learning Phase of Machine Learning
- Inference from Model
- Machine Learning Deployment Pipeline
- Build a Predictive Model
- Training and Validation Sets: Splitting Data
- Determining the “estimated cost” by parameters
- Predict the “estimated cost” for arbitrary parameters
- Evaluation Metrics for Machine Learning Model
- Linear regression Predictive Models
- Find Open Datasets
- Loading large Datasets into Kaggle
- Data visualization and analysis in Kaggle
- Average postcode price on a San Francisco map
- Total cost of all building permits for the postal code
- Average “estimated cost” by type of housing
Topics for this course
Introduction
Introduction00:03:31
Part 1. Python. 1st Dataset. PDF files. Tika OCR. Regular Expression. Array und Function
Part 1. Pandas DataFrame. Kaggle. Jupiter Notebook.
Part 1. Independent Work Tasks. 2nd Dataset.
Part 1. GitHub. Desktop GitHub
Part 2. Python. PyTesseract OCR. Regular Expression. Array und Function.
Part 2. RegEx. Regular Expression in Python.
Part 2. Kaggle. Jupyter Notebook.
Part 3. Big Data Storage and MySQL.
Part 3. Practice. Export Excel worksheet data to a MySQL table
Part 3. A Storage System for Big Data. Hadoop.
Part 3. Practice. How Apache Spark makes your slow MySQL queries 10x faster.
Part 4. The Data Visualisation Tools. Introduction
Part 4. Practice. Data Visualization with Python. Kaggle and Jupyter Notebook.
Part 4. Online Data Visualization Tools. Introduction and getting started.
Part 5. Machine Learning. An Introduction.
Part 5. Practice. How does machine learning work?
Part 5. Workflow of a Machine Learning project.
Part 5. Practice. San Francisco – explore Building Permits Data. Build Predictive Model.
Similar Courses

REVIT to ASANA. BIM Kanban & Gantt Chart Construction Planning 📚 15 Lessons
Revit – BIM Project Management with 4D Time and 5D Cost 📚 16 Lessons

Collect Data. Convert Scanned Documents to Text. Extracting Data from Contracts and Receipts. 📚 10 Lessons
Store and Process Project Data and Big Data. From Excel to MySQL and Spark. 📚 8 Lessons
Visualization of Project Data in Construction. Basic Data Visualization Tools. 📚 8 Lessons
Machine Learning in Construction. Predicting the Time and Cost of Projects . 📚 9 Lessons
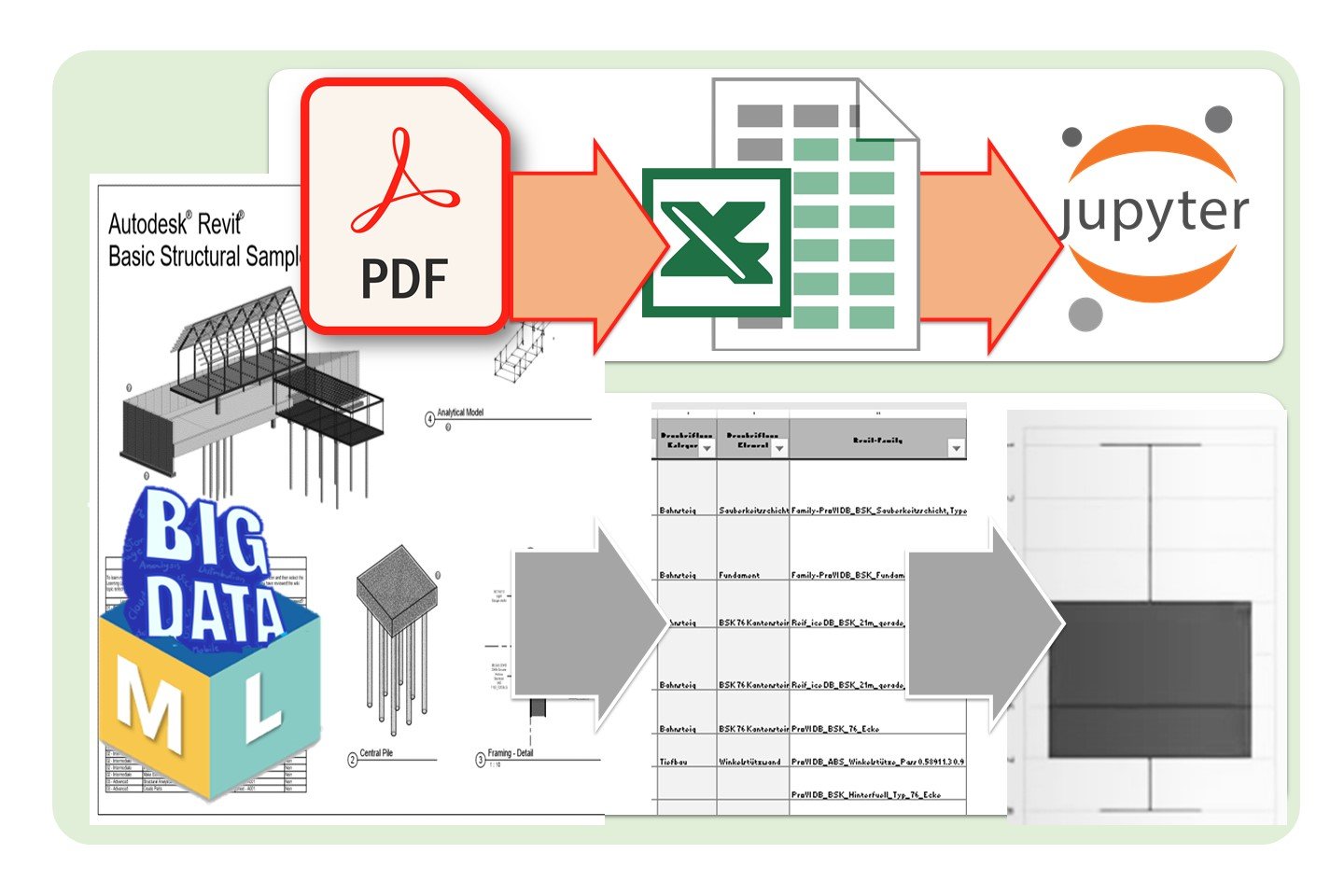
Big Data. Extract Data from PDF Drawings and Documents. PDF – Excel – Charts and Graphs. 📚 10 Lessons
Contact

- Email: boikoartem@gmail.com